Introduction
I’ve been signed up to Assembly Coffee’s Flavour Index for a few months now. It’s a great service that allows us to try a wide variety of different coffee from around the world, with a different type being delivered to our door each month. Besides the coffee being of a fantastic quality, I enjoy that Assembly takes the time to provide you with interesting information about each coffee:

Aa self confessed Notion nerd, this made me wonder:
Could I store this information in a database to have a history of all the coffee I’ve tried?
Notion provides an API for integration so it should be possible.
The high level steps were as follows:
- Capture the coffee information each month
- Publish the information to a Notion database
- Send a notification once it’s published
I’m most comfortable with AWS, and this seems like something that could be done easily and cheaply with AWS Lambda.
Don’t rely on humans
The original approach I took for this was to scrape the information on the webpage using BeautifulSoup. This seemed like a good approach considering the authors of the page prefix the coffee information with a descriptor, e.g. Producer - Producer Name. With a bit of matching and regex I could grab the information. I wrote a simple Python application hosted on Lambda to perform the steps, then used an EventBridge schedule to trigger it monthly.

So, all is good in the world and this will work forever right? Wrong.
This worked for the first month then broke. I noticed that the page authors had a tendency to make small changes in the descriptors. One month it would be “Producer” and the next it would be “Producers”. I considered emailing them but I’m fairly sure supporting my application is not high on the developers list. So I needed a different approach to deal with inconsistencies, maybe one that involves those LLM things everyone keeps talking about?
Robots are better
A friend recommended that this might be easily solved by an LLM that could deal with small changes. I was interested in learning how to integrate with LLM’s directly through the API anyway, so it made sense (if a bit overkill). However you can’t just ask ChatGPT to get this information from the webpage because it has historical data. Luckily the prompt size for ChatGPT is quite large, so we can just send the whole webpage over and ask it to find the stuff we care about.
The new application works by:
- Curls the Assembly Flavour Index page
- Sends the page with a prompt to pull out the interesting pieces of information and return them in a dictionary
- Generates an interesting fact about coffee production in the country of origin
- Inserts this information into Notion
- Generating an email with the information using Amazon Simple Email Service (SES)
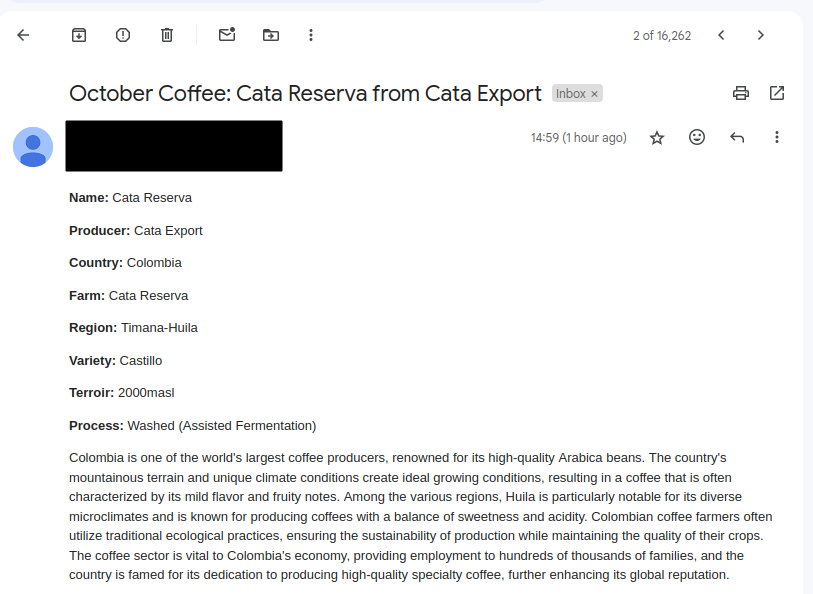
The application now seems to be working well. I’ve made the repo public if anybody happens to have the extremely specific requirement that this addresses. All in all it was fun to put together, and now I can look back at my database to reminisce about the delicious coffee I had back in April.